一些废话
最近想碰下分布式,于是开始鼓捣 6.824 。国外公开课质量是真滴高,每节课都是论文讨论班… lab 配套的测试也很给力。不过最近很少看视频了,关于 6.824 都是在调这个 lab2 。当然不是对着代码硬调,只是干别的事无聊了就来看看自己写的代码问题在哪。成老师指出上下文切换成本大,其实还好,只要能把一个事情阶段性地干好,现场恢复还是挺快的。
我做的是 2020 版的,为啥 2022 年还做 2020 呢?因为我看的视频是 2020 ?另一方面,2022 好像多了 log compaction ,而弱鸡如我只想要一些分布式的 general experience 。
一些不成熟建议
这里主要说下写 lab2 的心路历程。首先,整体而言,以下几点比较重要:
- 论文读仔细,特别是 figure 2
- 好好看 raft guide
- 把助教那个视频也给仔细瞧瞧
比如我知道了要多打 log ,并且可以去测试代码里面打 log ,又比如可以看测试代码的逻辑在整些啥幺蛾子。看到了却还踩的坑,包括但不限于:
- 持有锁的 goroutine 进入睡眠
- 持有锁的 goroutine 向
applyCh投信息,这可能会被 block
一开始 2B 不能每次都过… 是因为 TestBackup2B 这个用例一直卡着(10 次大概能过 8 次),因为这个用例比较复杂,我安慰自己选主失败很正常,于是停止挣扎。跑 2C 发现有个例子死活过不去,看了下其实是 TestBackup2B 的加强版(类似跑了多次 TestBackup2B ,比如说在这个场景下选主失败率是 20%,那么跑 n 次就是 1 - 0.8^n ,5次基本每次都跪)。后面我会单拎出来分析 TestBackup2B。
日志信息尽量详细点,多打的无关日志可以手动删或写脚本干掉。
一些踩过的坑
接着,我说下我踩的一些坑。这里把笔记直接贴过来了…
2A
- remember reset ticker when you vote, not just when receive heartbeat!
2A 还是相对简单的,一开始实现的领导选举有点小问题,但其实是到 2B 才炸的。
2B & 2C
-
separate heartbeat in a single goroutine!
-
make RPC call idempotent, e.g. for a success reply of
AppendEntriesfrom client, do not blindly incrementnextIndex[]bylen(args.Entries), you may send the same request several times -
when a 5-group lose 2, a 3-group’s leader election is a little hard
一开始我把超时选举和领导心跳包放在一起,这样导致心跳发少了,动不动就重新选举。当把心跳包单独拉到一个 goroutine 就好多了。
第二点是要保证你的 RPC 是幂等的,同一个 entry 你可能发了多次,follower 响应 success ,你不能疯狂叠 buff 一直递增 nextIndex 和 matchIndex 。
case study: 2B back up
没错,第三点是针对 TestBackup2B(后面发现的 bug 基本都是这种场景或者是它的加强版)。这个测试在弄啥呢?这个代码有点长,有两个点会有大量的成功 commit 。在第二点之前,需要从三个 candidate 里选出一个 leader 。然而因为有两个小伙子是刚断线重连的,所以他们没有成功 commit 的内容,意味着只有另一个小伙子能成为 leader 。注意到要获取 majority 的票,于是在只剩下三人的情况下要拿到所有的票,跑这个测试的时候经常在这里蚌住。
func TestBackup2B(t *testing.T) {
servers := 5
cfg := make_config(t, servers, false)
defer cfg.cleanup()
cfg.begin("Test (2B): leader backs up quickly over incorrect follower logs")
cfg.one(rand.Int(), servers, true)
// put leader and one follower in a partition
DPrintf_Test("put leader[%d] and one follower in a partition")
leader1 := cfg.checkOneLeader()
cfg.disconnect((leader1 + 2) % servers)
cfg.disconnect((leader1 + 3) % servers)
cfg.disconnect((leader1 + 4) % servers)
// submit lots of commands that won't commit
DPrintf_Test("submit lots of commands that won't commit")
for i := 0; i < 50; i++ {
cfg.rafts[leader1].Start(rand.Int())
}
time.Sleep(RaftElectionTimeout / 2)
DPrintf_Test("disconnect leader[%d] and one follower", leader1)
cfg.disconnect((leader1 + 0) % servers)
cfg.disconnect((leader1 + 1) % servers)
// allow other partition to recover
DPrintf_Test("allow other partition to recover")
cfg.connect((leader1 + 2) % servers)
cfg.connect((leader1 + 3) % servers)
cfg.connect((leader1 + 4) % servers)
// lots of successful commands to new group.
DPrintf_Test("lots of successful commands to new group.")
for i := 0; i < 50; i++ {
cfg.one(rand.Int(), 3, true)
}
// now another partitioned leader and one follower
leader2 := cfg.checkOneLeader()
other := (leader1 + 2) % servers
if leader2 == other {
other = (leader2 + 1) % servers
}
DPrintf_Test("disconnect %d", other)
cfg.disconnect(other)
// lots more commands that won't commit
DPrintf_Test("lots more commands that won't commit")
for i := 0; i < 50; i++ {
cfg.rafts[leader2].Start(rand.Int())
}
time.Sleep(RaftElectionTimeout / 2)
// bring original leader back to life,
DPrintf_Test("bring original leader back to life,")
for i := 0; i < servers; i++ {
cfg.disconnect(i)
}
cfg.connect((leader1 + 0) % servers)
cfg.connect((leader1 + 1) % servers)
cfg.connect(other)
// lots of successful commands to new group.
DPrintf_Test("lots of successful commands to new group.")
for i := 0; i < 50; i++ {
cfg.one(rand.Int(), 3, true)
}
// now everyone
DPrintf_Test("now everyone")
for i := 0; i < servers; i++ {
cfg.connect(i)
}
DPrintf_Test("cfg.one")
cfg.one(rand.Int(), servers, true)
cfg.end()
}
update your stale term and convert to follower
一开始我以为是 timer 不够分散(随机),所以拉大了 election timeout 的取值区间,同时增加心跳包的频率。然而 2C 的测试让我发现我没有践行“发现 RPC 的 term of request & reply 比自己大时,要更新自己的 term”。错误示范:
if rf.CurrentTerm < args.Term && if rf.isCandidateUp2Date(args) {
// if our term is smaller
rf.CurrentTerm = args.Term // stole the term
...
}
应该改成如下,2B 好像没问题了?接着开始 apply error(leader 尝试覆盖已经 commit 的信息)。这里一开始更新 term 时没有同时切换为 follower, 考虑一种场景,当一个 stale leader 重连后更新 term 但不切成 follower ,那么就会出现脑裂(split brain),会让 follower 误认为它是 leader,然后删错日志。
if rf.CurrentTerm < args.Term {
// if our term is smaller
rf.CurrentTerm = args.Term // stole the term
rf.convert2Follower() // remember this...
// but we may not vote for it
if rf.isCandidateUp2Date(args) {
...
}
...
}
do not reset your ticker easily
下一个问题是,在一个 5-group 2 个机器失联,剩下三个只有一个拥有 up-to-date log,选主要拿到三票所以只有它能成功。重新跑 2B 100 次发现有一次选主一直失败,是因为 convert2Follower 中重置了 election timer ,这是不合理的,会降低选举的 liveness。在原论文只有三种情况重置 ticker(虽然我好像多做了其他地方的 reset):
- 为别人投票,注意你得把票投出去
- 接到 leader 的心跳包
- 超时后你开始了一轮选举
func (rf *Raft) convert2Follower(reason string) {
if rf.serverState != FOLLOWER {
DPrintf("[%d] convert to follwer because %s", rf.me, reason)
rf.serverState = FOLLOWER
rf.VotedFor = -1
}
rf.lastHeartbeat = time.Now() // error here, naive!
}
说到底踩了这么多坑,还是没有深刻落实 Figure 2,但每次发现 bug 前我都觉得我尽力了…
case study: 2C Figure 8(unreliable)
我以为终于搞定了… 那天学校雪景看着也贼舒服,然后发现回来还是有问题。
figure 8(unreliable) 是 2C 的一个测试,看起来好像挺多人都栽在这里。关于 figure 8 详情可以看论文,unreliable 指的是网络延迟丢包,这里提供我在看日志找 bug 的一些经验,不一定有用。
论文提到,当日志和 leader 发生冲突时
- 删除冲突的日志,对应包括
prevLogIndex及后面的日志 - 发送冲突的 term ,以及该 term 对应的第一个 index
那么如果 follower 的日志长度不足 prevLogIndex 呢?这个 index 要根据哪个 term?有以下选择:
- follower 的 last index 即日志长度-1(从0开始)
-
leader 的
prevLogTerm,如果没有再选择 1 - follower 最后一个日志的 term
想想这个 index 用来干嘛,leader 接到这个响应后会从这个 index 发日志。直觉上从上到下,日志数量单次发送量会越来越大,同时所需次数也会少一些。
第一种做法比较无脑,通过率大概是 380/400 (可能还有其他因素)。考虑如下情景:
这里的
cterm指conflictTerm,cindex指firstIndexOfConflictTerm,参考论文。
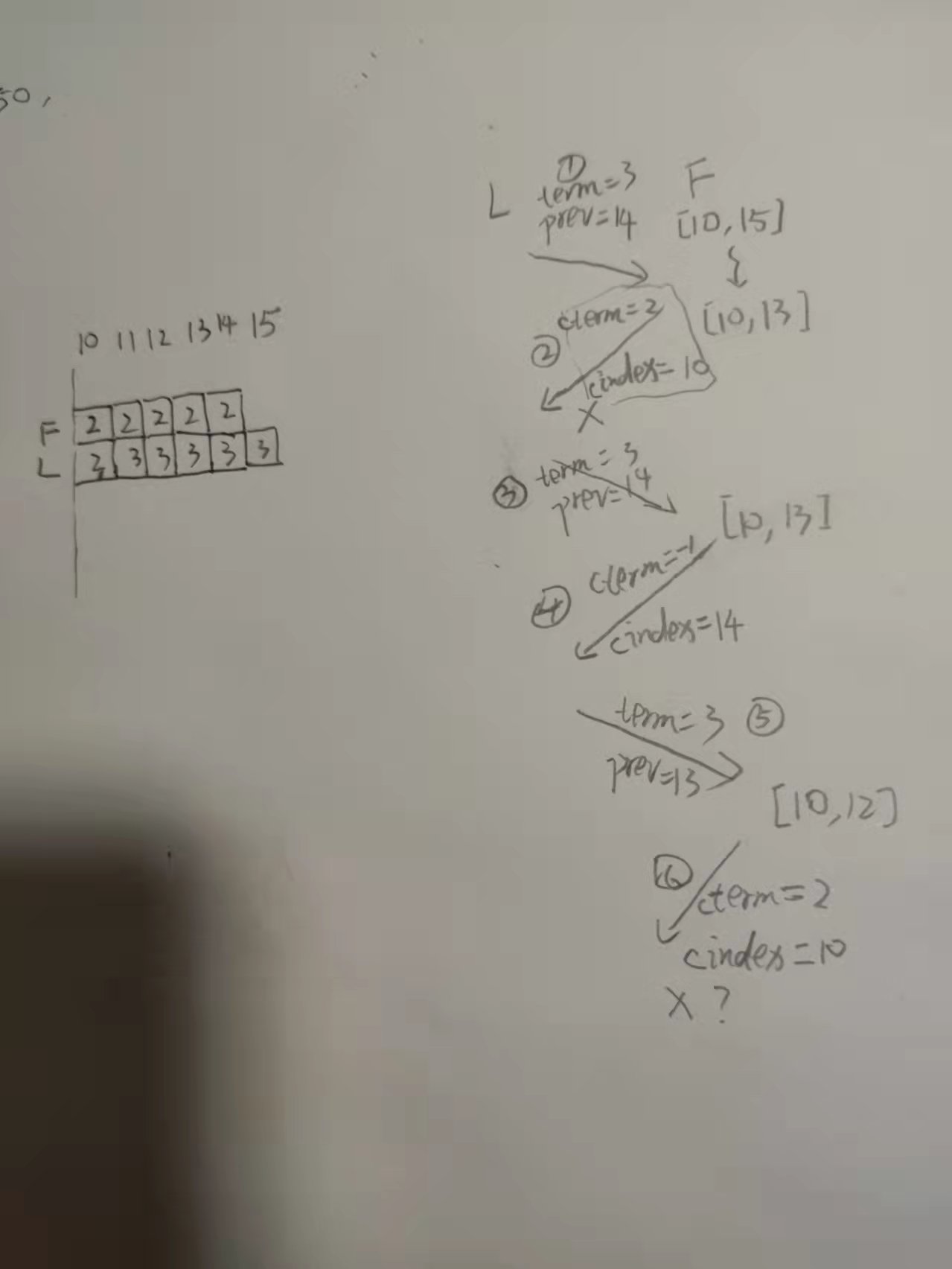
序号为发生顺序,左图为 L(leader) 和 F(follower) 对应的日志。在接到请求 ① 之后,F 砍掉了日志 14,但回去的请求丢包了。L 会重发请求 ③ ,参数同 1(因为没有更新 nextIndex)。若采用方法1,因为丢包会多了一轮 ④⑤ 请求的拉扯(如果请求⑥再丢包又得继续拉扯)。方法3应对这种网络丢包感觉很不错,虽然有可能覆盖没问题的日志(但不会有正确性问题),会增加多余的传输量。现在个人感觉这个比较符合直觉。。。
当前我的实现是方法2。事实上,你会发现方法2和1在这种场景下表现大差不差,但从1改到2,跑了将近一百次测试都没出现问题… 并且我没想到其他 2 比 1 好的场景(不想动脑了…)。考虑到这种情况,在2的基础上,我做了一点小改进。在砍冲突日志的时候,保留 preLogIndex 这个日志(如果有的话),这样的话即使丢包也会让这个请求产生一种幂等的效果:
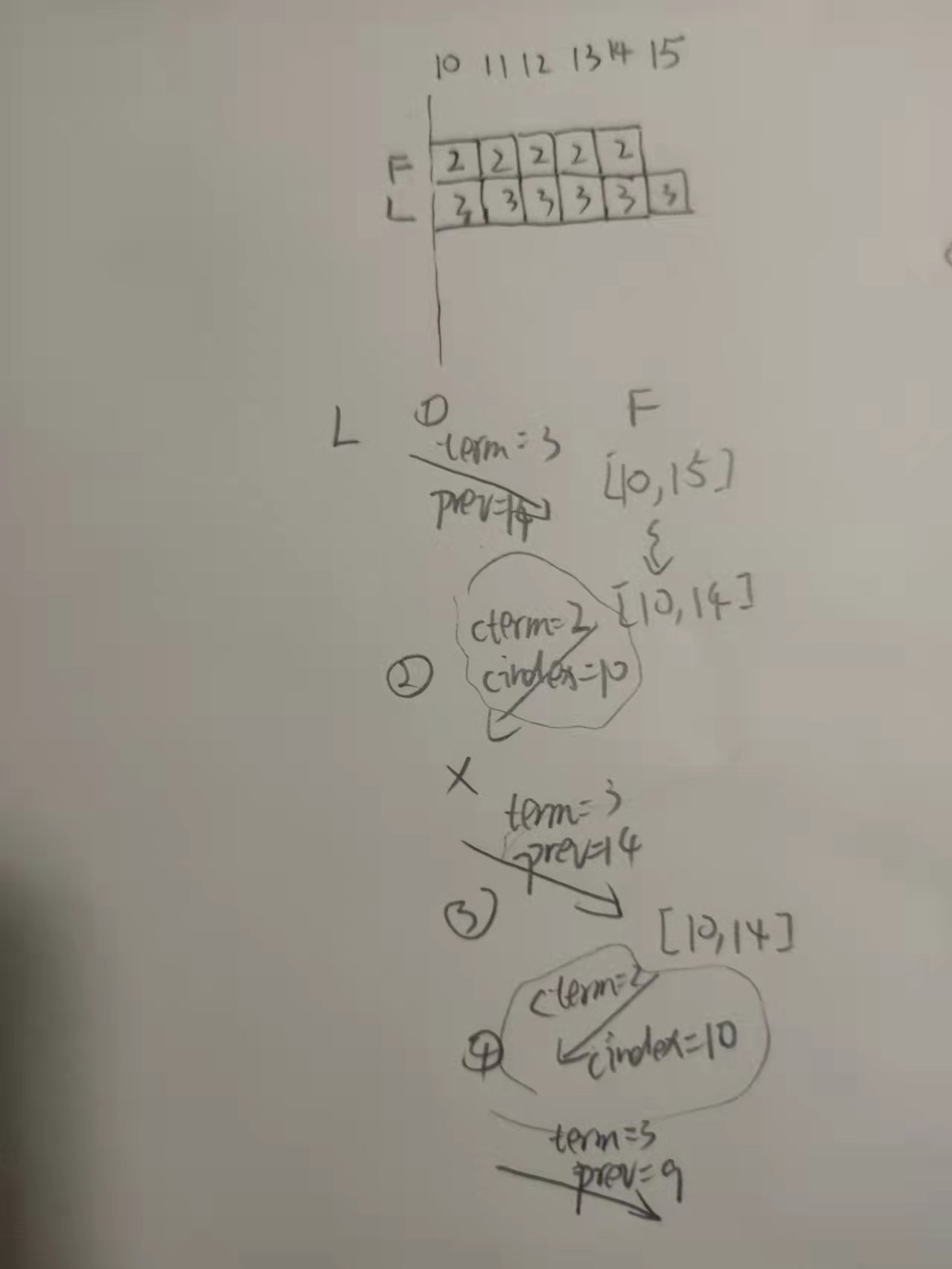
注意保留这个冲突的日志没啥问题,在下一轮 append 就会消灭掉。
重跑 2A/B/C 400 次无一 fail,我们都有光明的未来。
最后
这门课还是很推荐的,也让我深感测试的重要性。尤其对于分布式来说,毕竟“模型正确不代表代码正确”…